

For businesses beginning a cloud-first digital transformation or modernization strategy, the challenges of planning and finding the right expertise to execute these plans can feel daunting.
These challenges are made even tougher by the rapid growth of tools and technologies in the ecosystem, and how quickly they keep evolving.
On top of this, the ever-changing fields of platform and cloud engineering, DevOps, DataOps, and more make executing these strategies feel like navigating a maze.
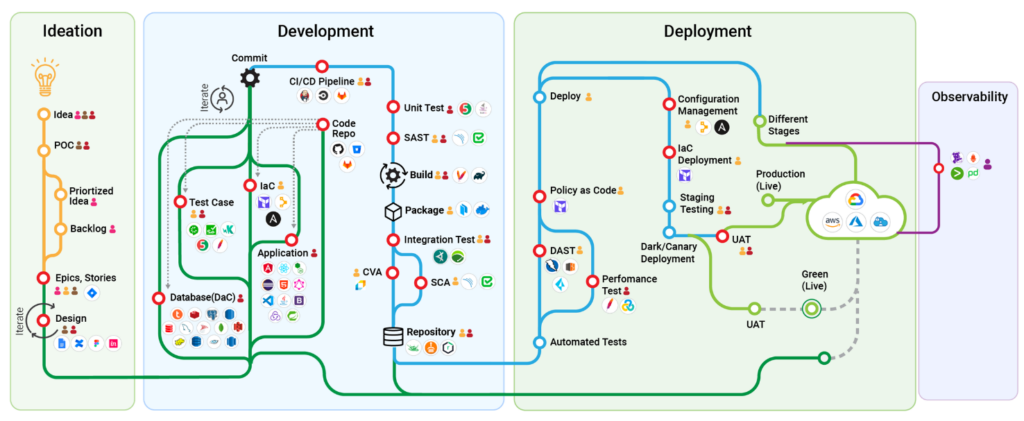
At its core, the technical side of a digital transformation journey boils down to three main areas: data products, digital software products, and secure infrastructure/platform capabilities.
Harnessing the full potential of data
The invaluable role of data for businesses has never been clearer, especially in today’s rapidly evolving AI world. Companies that don’t focus on leveraging data to optimize their operations and decision-making risk falling behind their competitors.
The focus and attitudes towards how to harness business value from data have evolved over time, with emphasis being placed today on augmented analysis – defined by Gartner® as
“the use of enabling technologies such as machine learning (ML) and artificial intelligence (AI) to assist with data preparation, insight generation and insight explanation to augment how people explore and analyze data in analytics and BI platforms.”
The journey towards augmented analysis

The essential architectures driving today’s active metadata era with advanced analytics and ML/AI capabilities are:
- Data Fabric – active metadata-driven data integration and analysis of disparate data sources through intelligent orchestration and automation.
- Data Mesh – a federated and decentralized approach to analytical data production, management, and governance.
- Data Lakehouse – combines and unifies the architectures and capabilities of a data warehouse and a data lake on a single platform.
Data Fabric and Data Mesh architectures can work well together. Data Mesh sets the rules and governance for data-sharing activities, which are then implemented by Data Fabric.
Similarly, Data Fabric complements Data Lakehouse by enabling the orchestration needed to produce or consume data within a Data Lakehouse.
Data Fabric architecture
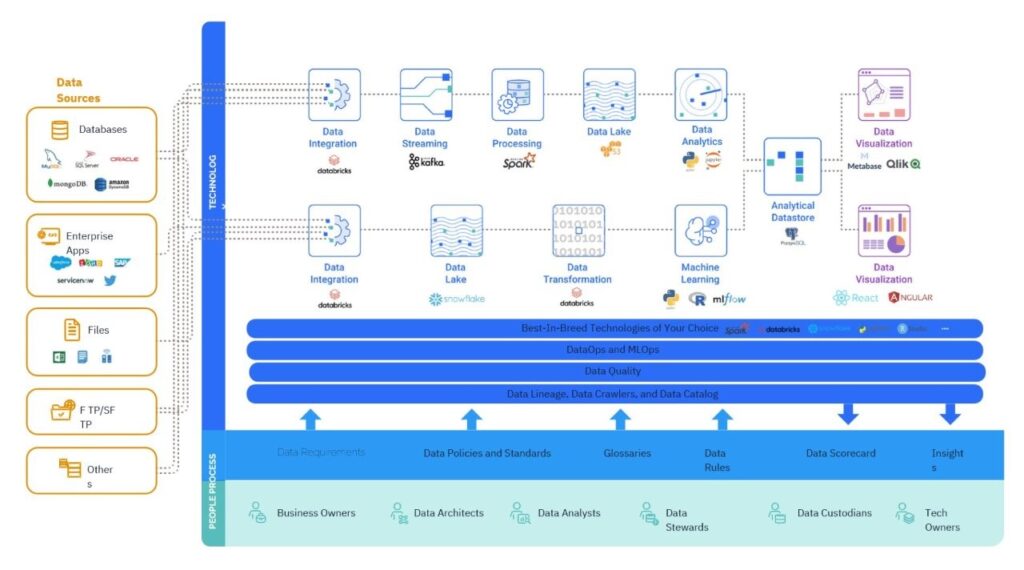
Businesses that are focused on finding ways to easily adopt, implement, and keep up with these evolving data architectures as part of their cloud-first digital transformation strategies, will be well-positioned to keep up with or even lead their competitors.
Software products – adapting to evolving practices
Software engineering practices and methodologies have evolved over time, requiring organizations to adopt new tools and technologies, such as requirements management, design/modeling tools, and source code management systems.
This constant change places an extra burden on software engineering and development teams, who must continuously adapt and learn new tools to work efficiently.
Creating data products, including DataOps solutions, now increasingly relies on software engineering practices, including DevOps.
The rapid growth of development technologies, open-source libraries, package managers, languages, and services, along with factors like remote teams spread across various time zones, language barriers, and cultural differences, makes the demands on the average software engineering team almost overwhelming.
Businesses that tackle this challenge as part of their digital transformation strategy, aiming to continuously improve the developer experience for their software engineering teams, through self-service enablement, will see significant benefits in productivity and talent retention.
Gartner’s Top 5 Strategic Technology Trends in Software Engineering for 2024 research report states the value in quantitative terms:
Boosting developer experience through self-service platforms
“Gathering insights on developer experience has become a top priority for software engineering leaders seeking to improve their organization’s effectiveness. In the 2023 Gartner Developer Experience and Ecosystems Survey, teams with high-quality developer experience reported they are:
- 33% more likely to attain their target business outcomes
- 31% more likely to improve delivery flow
- 20% more likely to intend to stay with their employer”
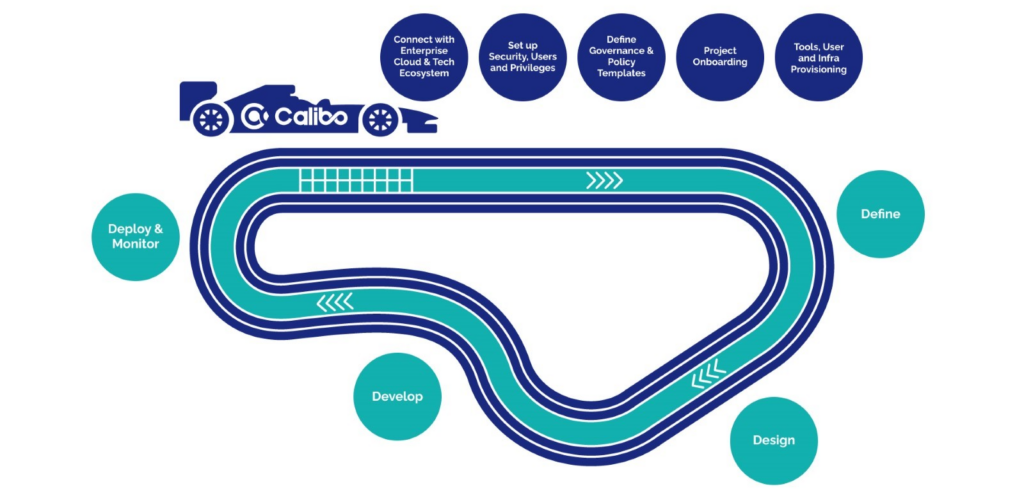
Driving efficiency with platform teams: Platform teams have become increasingly critical to businesses that are involved in implementing cloud-first digital transformation initiatives.
They work closely with cloud infrastructure, security, and architecture teams to implement platforms aimed at:
- Simplifying engineering to accelerate data and software product build.
- Enabling self-service provisioning of tooling, environments, infrastructure and more by product teams.
- Providing end-to-end tech stack orchestration & automation to boost development team efficiency and productivity.
- Promoting collaboration between business and technical teams through a single pane of glass for all stakeholders involved in the data and software product delivery process.
- Enhancing security and governance through standardization and policy-driven guardrails.
- Enabling monitoring and centralized observability and insights to provide oversight and support continuous process improvements.
Self-service platforms developed by platform teams are key to enhancing the developer experience and boosting productivity, ultimately speeding up product delivery.
These platforms are even more effective when they include additional features for creating data products and managing product releases, much like Calibo’s platform offers.
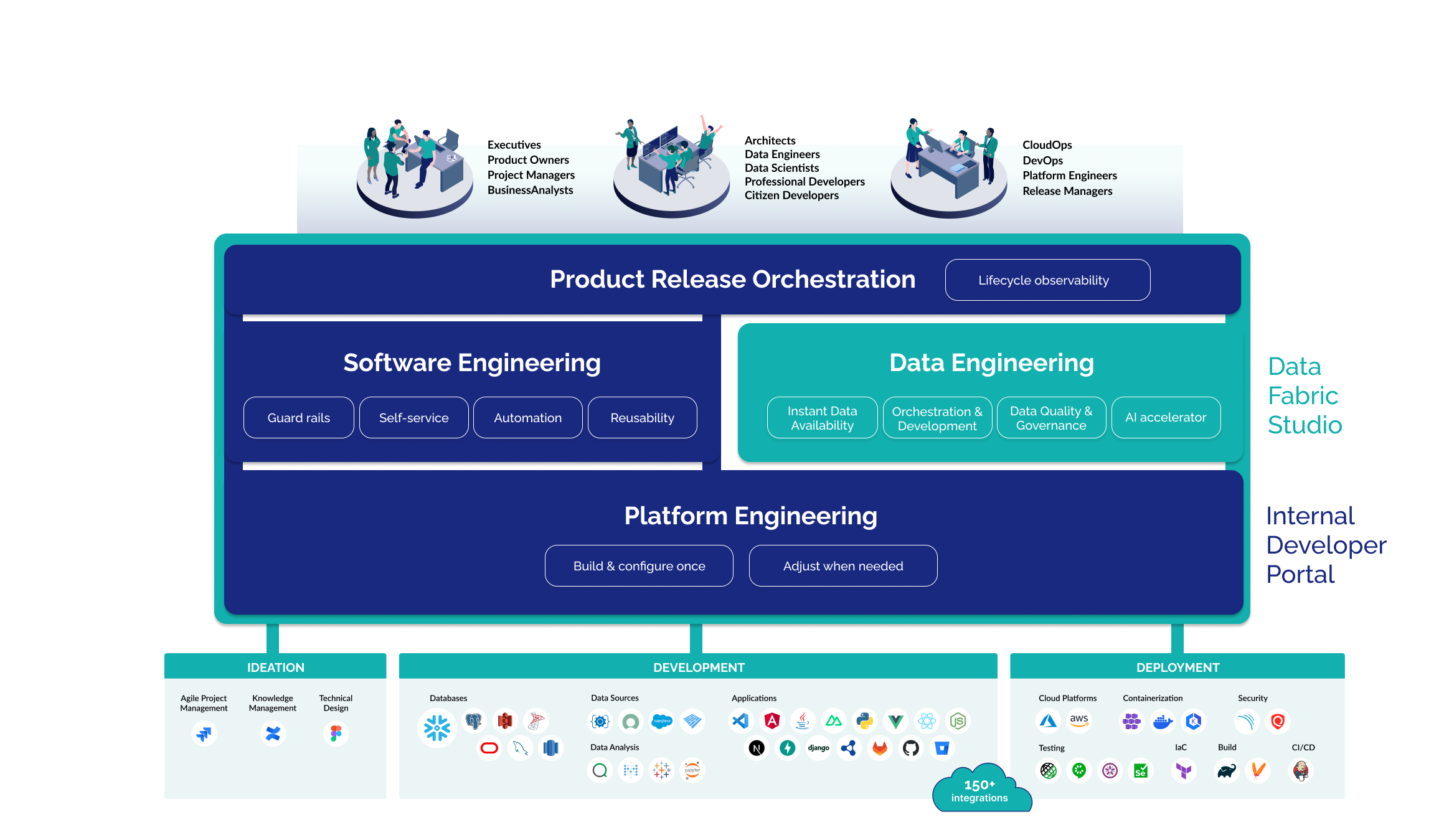
Use case: Accelerate Data Fabric with Calibo’s self-service platform and Snowflake
- Scenario: Tasty Bytes is a fictional global food truck franchise operating in multiple cities across various countries. It has operational data spread across multiple repositories: food truck data in SAP; customer and order data spread across several SFTP drives; and menu, franchise, country and location data in a MySQL database.
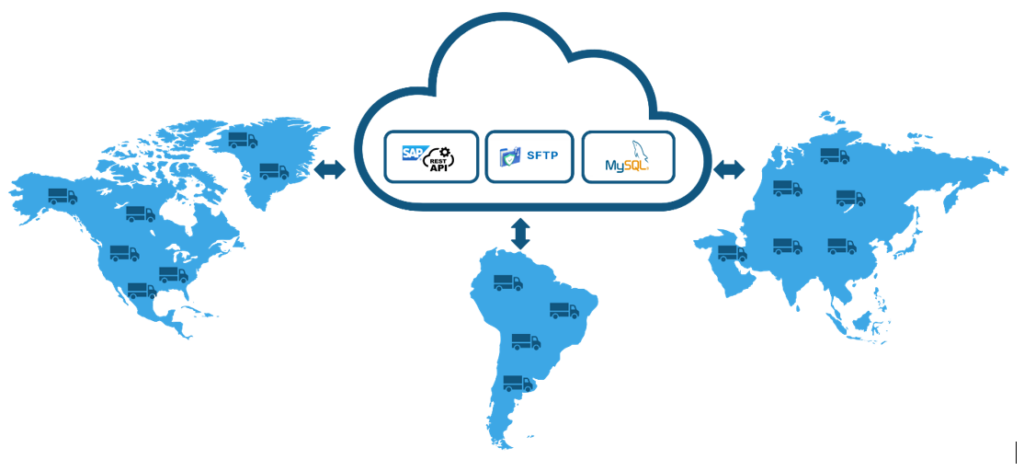
- Challenge: A fragmented data landscape is slowing down optimized, AI-driven operations and decision-making.
- Expected outcome: Implement a solution to reduce customer churn through the elimination of data silos and implementation of ML/AI algorithms and models.
- Goal: Accelerate the delivery time of the solution by 50% through Calibo’s self-service platform and Snowflake.
- Use case development: To bring this use case to life, data engineers will start by using Calibo’s Data Fabric Studio to build a data pipeline.
This pipeline will gather and organize data from the various Tasty Bytes sources and store the unified data in Snowflake for consumption by other business users. This setup will enable data scientists to speed up their work by leveraging the unified data, allowing them to focus on creating their own straightforward data pipeline in Snowflake, enriching the data, developing and training their ML algorithms, running experiments, and deploying their solutions and models.
Here are the steps involved in developing the use case:
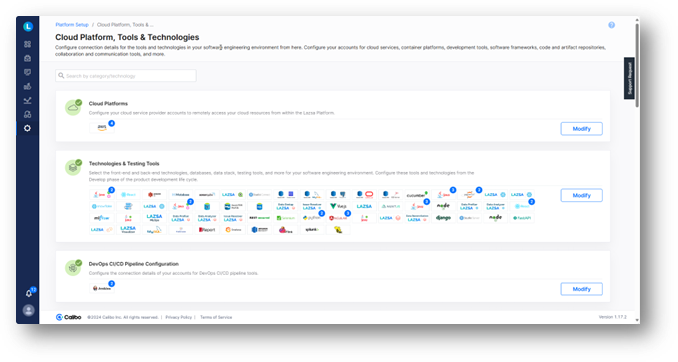
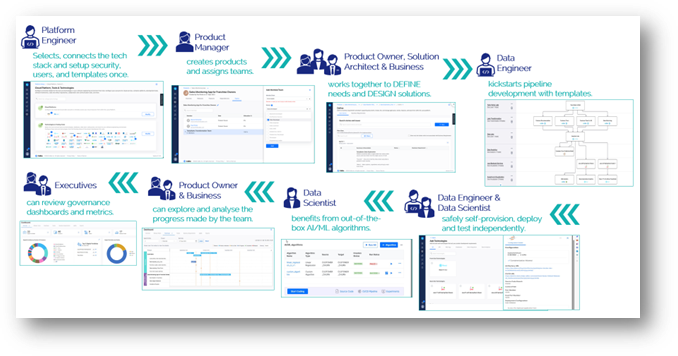
1. Platform engineering: Accelerating the use case development starts with platform teams setting up configurations to enable access and orchestration to the 150+ integrated cloud platforms and tech stacks, including AWS, Snowflake, JupyterLab, GitLab and more.
They then set up roles and import users from directory services like Azure Active Directory and assign them to those roles within the platform. Finally, they enable capabilities to automate mundane, repeatable tasks, like CI/CD pipelines, and configure standardization policies required to provide guardrails to the development teams.
This step is typically performed upfront once, reused many times by development teams, and refined over time – to keep up with changes in the technology ecosystem, accommodate new integrations, as well as feedback from the development teams.
The goal of the platform team’s work is to give data and software development teams the self-service tools they need to start and define their projects, set up their own development environments, and manage deployments. This reduces their reliance on operations teams and speeds up the time it takes to develop use cases.
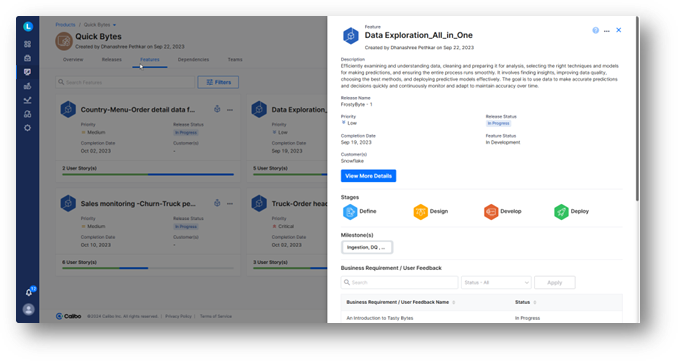
2. Product management: Product owners collaborate with the business to setup their digital product portfolios on the platform and configure their products and related features within those portfolios. In our case, they will create a product called Quick Bytes with multiple features.
They will create a team called the Tasty Bytes Transformation Team, which includes a data engineer and a data scientist, and assign this team to the Quick Bytes product. They will also set milestones for the product and its features, create a release schedule, and link the product and features to releases within this schedule for better project governance.
They then collaborate with business analysts to define user stories in a Jira workspace and assign the user stories to the individual features within the Quick Bytes product. Architects, designers, and modelers then create and manage their architecture and design artefacts related to the product and features in Confluence and associate the wiki page with the product.
This provides a single-pane-of-glass for the team’s data engineer and data scientist to gain access to all they need—including the relevant context—to begin their development work immediately!
Additionally, pre-defined standardization policy templates are associated with the products to ensure the necessary infrastructure and architecture guardrails are in place.
3. Data engineering: A data engineer assigned to the Quick Bytes product gains instant access to the product and the Data Exploration All-in-One feature they’ve been assigned to work on by the product owner as soon as they login to the platform.
They can quickly review the user stories assigned to the feature in Jira, review any design artefacts in Confluence, and then jump right into developing their data pipelines in the Data Fabric Studio.
To accelerate their data pipeline development, they will first explore whether there is a reusable data pipeline template they could import and use as the starting point of their development work.
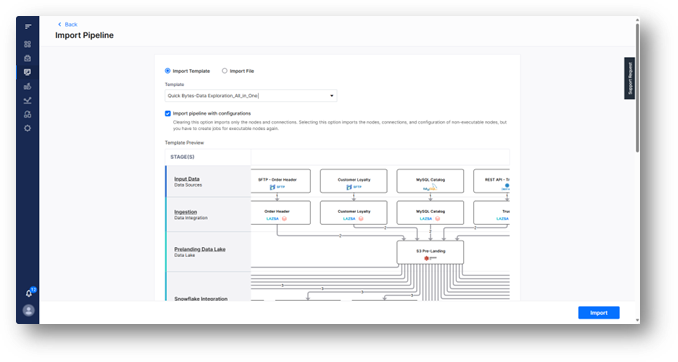
Once a data pipeline template is imported, the data engineer can review and validate the data sources included in the pipeline.
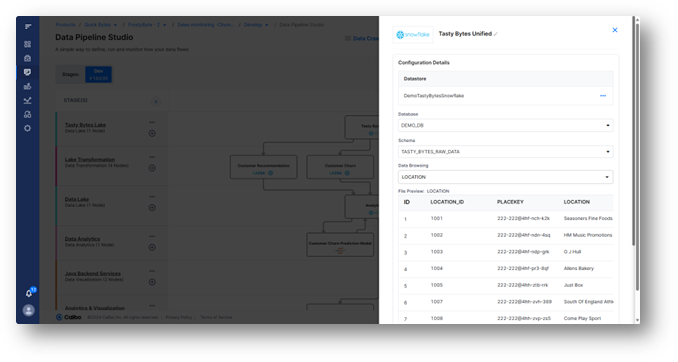
For example, a REST API connector can be used to preview and confirm the Tasty Bytes enterprise truck data stored in SAP – right from within the Calibo platform.
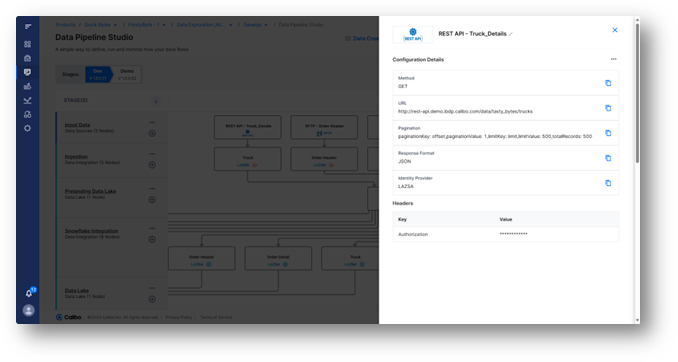
The same approach will be used to validate the source data stored in SFTP quickly. The data engineer can speed up their pipeline development by using reusable ingestion metadata catalogs.
These catalogs are created by data teams by setting up data crawlers to discover various data sources, gathering the data, and storing the discovered metadata in reusable catalogs.
In our case, the data engineer will benefit from reusing the existing metadata catalog created from crawling the MySQL database, which is part of the Tasty Bytes enterprise data landscape.
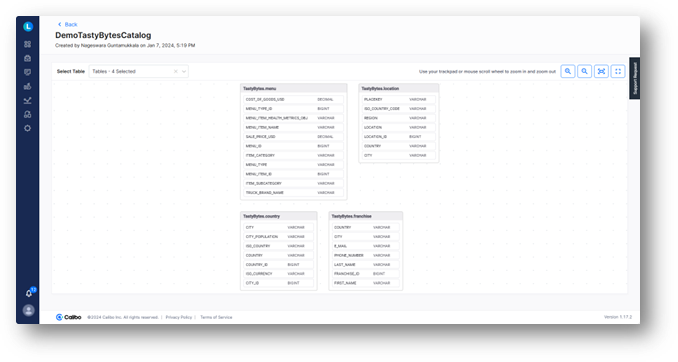
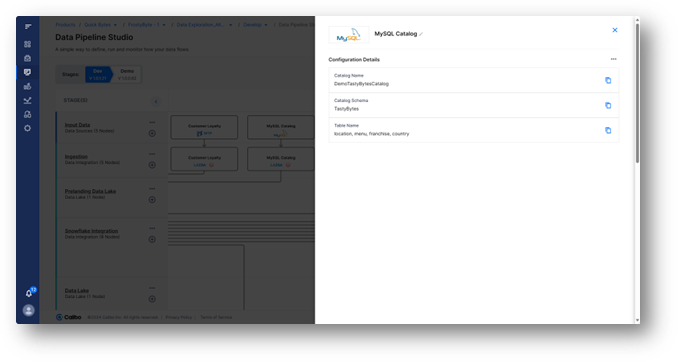
Once the data sources have been validated, the data engineer can define or adapt the data ingestion jobs to load the data into an AWS S3 staging data lake, then define or adapt the data integration jobs to copy the data from S3 to a prelanding data store in Snowflake.
Data quality jobs, as well as data transformation jobs to profile, analyze and resolve data quality issues can be adapted or added to clean, curate and unify the data in another Snowflake data store for consumption by downstream teams like data scientists and other software developers and business users.
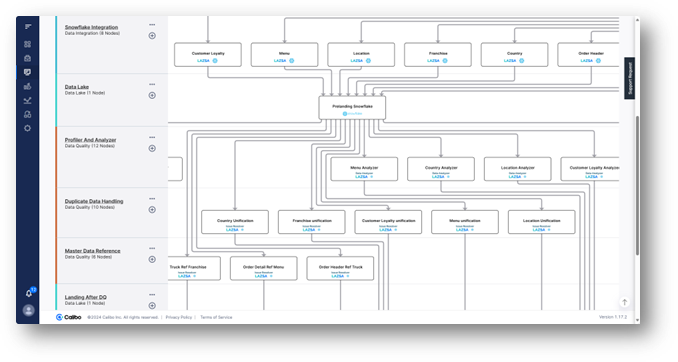
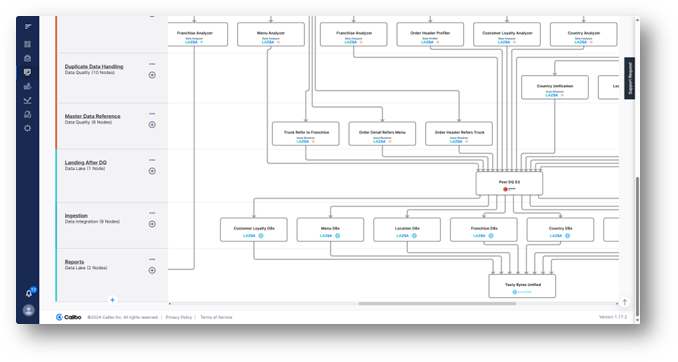
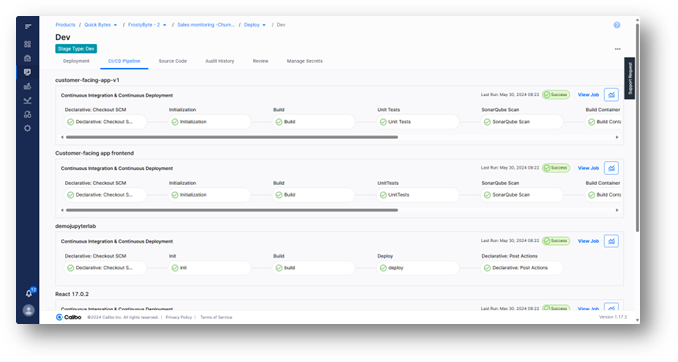
To finalize, the data engineer will publish the pipeline and run it immediately to test it. They can also choose to schedule and have it run later.
They also have the option to promote the pipeline to different environments (e.g. QA, Staging, Prod), configure time-out and notification rules, and more – all without any dependencies on operations teams and having to wait for days or weeks for their requests to be fulfilled.
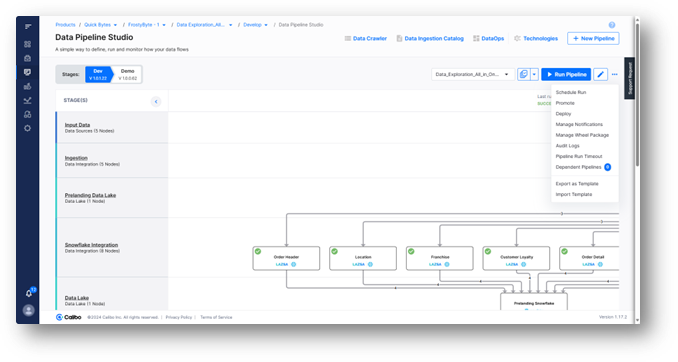
4. Data science: Like the data engineer, the data scientist assigned to the Quick Bytes product gains instant access to the product and the Sales monitoring -Churn-Truck performance insights feature they’ve been assigned to work on by the product owner as soon as they log in to the platform.
They can also quickly review the user stories assigned to the feature in Jira, review any design artefacts in Confluence, and then jump right into the development of their own simplified data pipeline and customer churn-related ML algorithm in the Data Fabric Studio.
They can also explore and import an existing data pipeline template to speed up their development work. More importantly, they won’t have to spend 80% of their time chasing down access to data sources and creating jobs to manage the data. The data engineer has already taken care of all that!
The data scientist will reuse the curated, unified data created by the data engineer as the starting point in their data pipeline, inspect the data to ensure it’s in the correct format, and then create or adapt analytics jobs to enrich the data for their model testing and experimentation work.
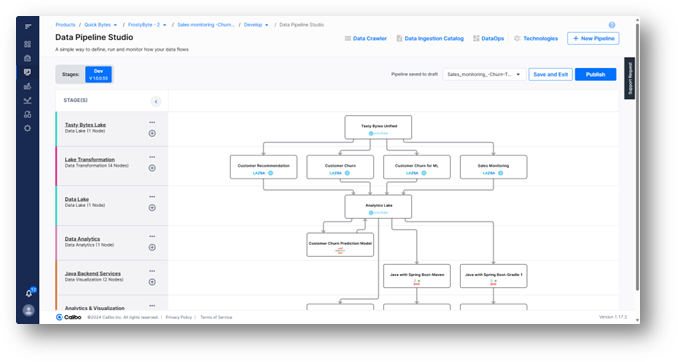
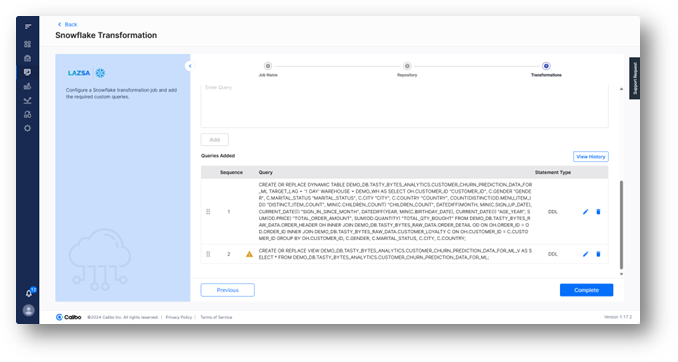
Once the pipeline has been run and the analytics lake is ready and tested, the data scientist can seamlessly integrate Python with JupyterLab, which has been pre-configured by the platform teams, directly into the pipeline.
They can then set up a Docker container for deployment and start developing and testing their algorithms— all without relying on the operations or infrastructure teams.
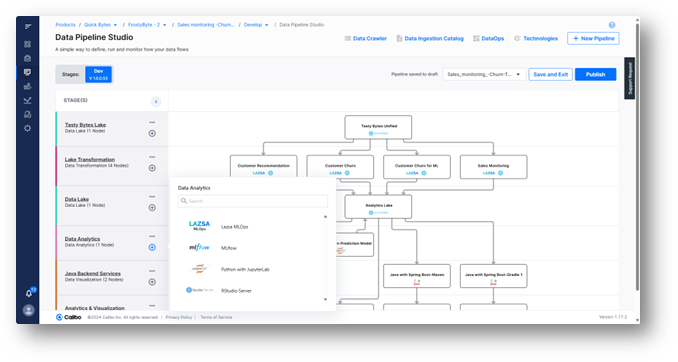
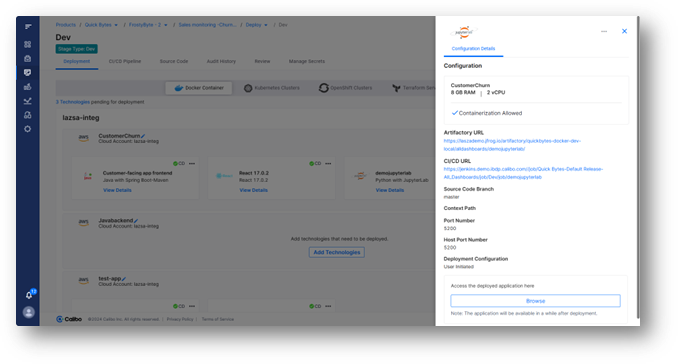
Also, once the Python with JupyterLab technology is added to the pipeline, a tech stack specific source code repository and CI/CD pipeline is auto-generated to support the data scientist’s work – based on configurations enabled by the platform teams. This further accelerates their development work.
To speed up ML algorithm development further, the Calibo platform offers several ready-to-use algorithms that data scientists can use as a starting point.
In our example, they might choose the Logistic Regression algorithm or create a custom one to develop customer churn algorithms.
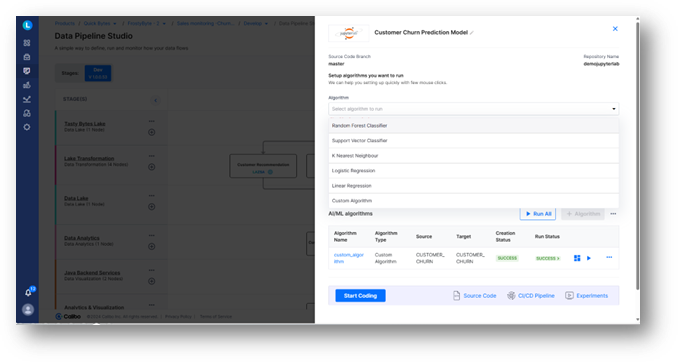
The data scientist can access JupyterLab directly from the platform to create and update their code. They are also able to initiate their experiment runs directly from the platform.
5. Project governance: Distracted developers are unproductive. To minimize distractions, the Calibo platform provides product owners and executives with up-to-date self-service access to dashboards and reports that can be used to track and govern their projects.
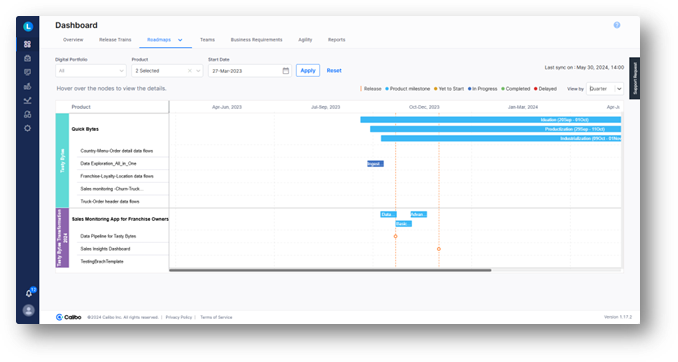
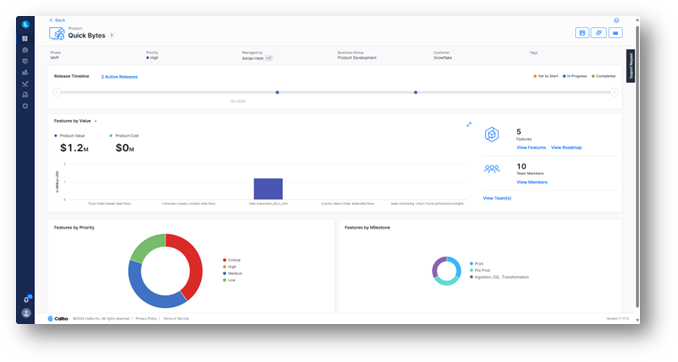
In conclusion
Developing Data Fabric with Calibo’s self-service platform and Snowflake can enable the delivery of ML/AI solutions in half the time.
The Calibo platform serves as a single pane of glass for a product development team to access all the tools they need to accelerate the development, testing, and deployment of data products and ML/AI solutions.
Acceleration is achieved through self-service capabilities enabled by platform teams through tech stack integrations, orchestration, automation, reusability, and guardrail policies.
Ready to find out how Calibo could help you build faster? Chat with one of our team here.
Trending articles

Overcoming the overwhelm: How Enterprise Architects can get more support for technology led innovation
Enterprise Architects (EAs), this one is for you! If the constant pressure to align tech strategies with business goals has you feeling cornered, you’re not alone. Today, you need to juggle numerous challenges—from siloed operations stalling projects to the rapid emergence of AI altering traditional frameworks. Yet, with the right strategies, EAs can transform…

Why combine an Internal Developer Portal and a Data Fabric Studio?
Are you asking this exact question? You’re not alone! Many IT leaders are on a quest to improve efficiency and spark innovation in their software development and data engineering processes. You may wonder why it’s a good idea to combine an Internal Developer Portal and a Data Fabric Studio – what’s the benefit? What IT…

Data mesh vs data fabric: Understanding key differences and benefits
One thing I love about working in tech is that the landscape is constantly changing. Like the weeping angels in Dr Who – every time you turn back and look – the tech landscape has moved slightly. Unlike the weeping angels, however – this progress is for the betterment of all. (And slightly less murderous).…

Best practices for developing AI solutions with a self-service platform
Enterprises are feeling increasing pressure to integrate Artificial Intelligence (AI) into their operations. This urgency is pushing leadership teams to adjust their investment strategies to keep up. Recent advancements in Generative AI (GenAI) are further increasing this pressure, as these technologies promise to enhance productivity and efficiency across the organization. For example, Gartner™ expects GenAI…
